
Python Programming Fundamentals for Class 11 and 12 – Basics Of Python
The previous chapter has given a brief introduction about Python’s user interface. This chapter will scratch the surface of Python programming and expose the basic elements which a programmer needs to know beforehand.
Variable, identifier and literal
A variable is a storage location that has an associated symbolic name (called “identifier”), which contains some value (can be literal or other data) that can change. An identifier is a name used to identify a variable, function, class, module or other object. Literal is a notation for constant values of some built-in type. Literal can be string, plain integer, long integer, floating point number, imaginary number. For e.g., in the expressions
var1=5 var2='Tom'
varl and var2 are identifiers, while 5 and ‘ Tom’ are integer and string literals, respectively.
Consider a scenario where a variable is referenced by the identifier a and the variable contains a list. If the same variable is referenced by the identifier b as well, and if an element in the list is changed, the change will be reflected in both identifiers of same variable.
>>> a=[1,2,3] >>> b=a >>> b [1, 2, 3] >>> a[1]=10 >>> a [1, 10, 3] >>> b [1, 10,3]
Now, the above scenario can be modified a bit, where a and b are two different variables.
>>> a=[1, 2, 3] >>> b=a[:] # Copying data from a to b. >>> b [1, 2, 3] >>> a[1]=10 >>> a [1, 10, 3] >>> b [1, 2, 3]
There are some rules that need to be followed for valid identifier naming:
- The first character of the identifier must be a letter of the alphabet (uppercase or lowercase) or an underscore
- The rest of the identifier name can consist of letters (uppercase or lowercase character), underscores (‘_’) or digits (0-9).
- Identifier names are case-sensitive. For example, myname and myName are not the same.
- Identifiers can be of unlimited length.
Token
A token is a string of one or more characters that is significant as a group. Consider an expression:
sum=6+2
The tokens in the above expression are given in table 2-1:
Table 2-1: Tokens
| Token | Token type |
| sum | Identifier |
| = | Assignment operator |
| 6 | Integer literal |
| + | Addition operator |
| 2 | Integer literal |
The process of converting a sequence of characters into a sequence of tokens is called “lexical analysis”. A program or function that performs lexical analysis is called a lexical analyzer, lexer, or tokenizer. A lexer is generally combined with a parser (beyond the scope of this book), which together analyze the syntax of computer language. Python supports the following categories of tokens: NEWLINE, INDENT, DEDENT, identifiers, keywords, literals, operators, and delimiters.
Keywords
The following identifiers (as shown as output in the following code) are used as reserved words (or “keywords”) of the language, and cannot be used as ordinary identifiers.
>>> import keyword >>> for kwd in keyword.kwlist: ... print kwd ... and as assert break class continue def del elif else except exec finally for from global if import in is lambda not or pass print raise return try while with yield
One can also check if an identifier is keyword or not using iskeyword () function.
>>> import keyword
>>> keyword.iskeyword('hi')
False
>>> keyword.iskeyword('print')
True
Operators and operands
An operator is a symbol (such as +, x, etc.) that represents an operation. An operation is an action or procedure which produces a new value from one or more input values^ called operands. There are two types of operators: unary and binary. Unary operator operates only on one operand, such as negation. On the other hand, binary operator operates on two operands, which includes addition, subtraction, multiplication, division, exponentiation operators etc. Consider an expression 3 + 8, here 3 and 8 are called operands, while V is called operator. The operators can also be categorized into:
- Arithmetic operators.
- Comparison (or Relational) operators.
- Assignment operators.
- Logical operators.
- Bitwise operators.
- Membership operators.
- Identity operators.
Arithematics operators
Table 2-2 enlists the arithematic operators with a short note on the operators.
Table 2-2: Arithematic operators
| Operator | Description |
| + | Addition operator- Add operands on either side of the operator. |
| – | Subtraction operator – Subtract right hand operand from left hand operand. |
| * | Multiplication operator – Multiply operands on either side of the operator. |
| / | Division operator – Divide left hand operand by right hand operand. |
| % | Modulus operator – Divide left hand operand by right hand operand and return remainder. |
| * * | Exponent operator – Perform exponential (power) calculation on operands. |
| // | Floor Division operator – The division of operands where the result is the quotient in which the digits after the decimal point are removed. |
The following example illustrates the use of the above discussed operators.
>>> a=20 >>> b=45.0 >>> a+b 65.0 >>> a-b -25.0 >>> a*b 900.0 >>> b/a 2.25 >>> b%a 5.0 >>> a**b 3.5184372088832e+58 >>> b//a 2.0
Relational operators
A relational operator is an operator that tests some kind of relation between two operands. Table 2-3 enlist the relational operators with description.
Table 2-3: Relational operators
| Operator | Description |
| == | Check if the values of two operands are equal. |
| != | Check if the values of two operands are not equal. |
| <> | Check if the value of two operands are not equal (same as != operator). |
| > | Check if the value of left operand is greater than the value of right operand. |
| < | Check if the value of left operand is less than the value of right operand. |
| >= | Check if the value of left operand is greater than or equal to the value of right operand. |
| <= | Check if the value of left operand is less than or equal to the value of right operand. |
The following example illustrates the use of the above discussed operators.
>>> a, b=20, 40 >>> a==b False >>> a!=b True >>> a<>b True >>> a>b False >>> a>> a>=b False >>> a<=b True
Assignment operators
Assignment operator is an operator which is used to bind or rebind names to values. Augmented assignment is the combination, in a single statement, of a binary operation and an assignment statement. An augmented assignment expression like x+=l can be rewritten as x=x+1. Table 2-4 enlist the assignment operators with description.
Table 2-4: Assignment operators
| Operator | Description |
| = | Assignment operator- Assigns values from right side operand to left side operand. |
| += | Augmented assignment operator- It adds right side operand to the left side operand and |
| assign the result to left side operand. | |
| -= | Augmented assignment operator- It subtracts right side operand from the left side operand |
| and assign the result to left side operand. | |
| *= | Augmented assignment operator- It multiplies right side operand with the left side operand |
| and assign the result to left side operand. | |
| /= | Augmented assignment operator- It divides left side operand with the right side operand |
| and assign the result to left side operand. | |
| %= | Augmented assignment operator- It takes modulus using two operands and assign the |
| result to left side operand. | |
| **= | Augmented assignment operator- Performs exponential (power) calculation on operands |
| and assigns value to the left side operand. | |
| //= | Augmented assignment operator- Performs floor division on operators and assigns value to |
| the left side operand. |
The following example illustrates the use of the above discussed operators.
>>> a,b=20,40 >>> c=a+b >>> c 60 >>> a,b=2.0,4.5 >>> c=a+b >>> C 6.5 >>> c+=a >>> c 8.5 >>> c-=a >>> c 6.5 >>> c*=a >>> c 13.0 >>> c/=a >>> c 6.5 >>> c%=a >>> c 0.5 >>> c**=a >>> c 0.25 >>> c//=a >>> c . 0.0
Bitwise operators
A bitwise operator operates on one or more bit patterns or binary numerals at the level of their individual bits. Table 2-5 enlist the bitwise operators with description.
Table 2-5: Bitwise operators
| Operator | Description |
| & | Binary AND operator- Copies corresponding binary 1 to the result, if it exists in both operands. |
| I | Binary OR operator- Copies corresponding binary 1 to the result, if it exists in either operand. |
| ^ | Binary XOR operator- Copies corresponding binary 1 to the result, if it is set in one operand, but not both. |
| ~ | Binary ones complement operator- It is unary and has the effect of flipping bits. |
| << | Binary left shift operator- The left side operand bits are moved to the left side by the number on right side operand. |
| >> | Binary right shift operator- The left side operand bits are moved to the right side by the number on right side operand. |
The following example illustrates the use of the above discussed operators.
>>> a,b=60,13 >>> a&b 12 >>> a|b 61 >>> a^b 49 >>> ~a -61 >>> a<<2 240 >>> a>>2 15
In the above example, the binary representation of variables a and b are 00111100 and 00001101, respectively. The above binary operations example is tabulated in table 2-6.
Table 2-6: Bitwsie operation
| Bitwise operation | Binary representation | Decimal representation |
| a&b | 00001100 | 12 |
| a | b | 00111101 | 61 |
| a^b | 00110001 | 49 |
| ~a | 11000011 | -61 |
| a<<2 | 11110000 | 240 |
| a>>2 | 00001111 | 15 |
Logical operators
Logical operators compare boolean expressions and return a boolean result. Table 2-6 enlist the logical operators with description.
Table 2-7: Logical operators
| Operator | Description |
| and | Logical AND operator- If both the operands are true (or non-zero), then condition becomes true. |
| or | Logical OR operator- If any of the two operands is true (or non-zero), then condition becomes true. |
| not | Logical NOT operator- The result is reverse of the logical state of its operand. If the operand is true (or non-zero), then condition becomes false. |
The following example illustrates the use of the above discussed operators.
> 5>2 and 4<8 True >>> 5>2 or 4>8 True >>> not(5>2) False
Membership operators
Membership operator is an operator which test for membership in a sequence, such as string, list, tuple etc. Table 2-7 enlists the membership operators.
Table 2-8: Membership operators
| Operator | Description |
| in | Evaluate to true, if it find a variable in the specified sequence; otherwise false. |
| not in | Evaluate to true, if it does not find a variable in the specified sequence; otherwise false. |
The following example illustrates the use of the above discussed operators.
>>> 5 in [0,5,10,15] True >>> 6 in [0,5,10,15] False >>> 5 not in [0,5,10,15] False >>> 6 not in [0,5,10,15] True
Identity operators
Identity operators compare the memory locations of two objects. Table 2-8 provides a list of identity operators including a small explanation.
Table 2-9: Identity operators
| Operator | Description |
| is | Evaluates to true, if the operands on either side of the operator point to the same object, and false otherwise. |
| is not | Evaluates to false, if the operands on either side of the operator point to the same object, and true otherwise. |
The following example illustrates the use of the above discussed operators.
>>> a=b=3.1 >>> a is b True >>> id(a) 30984528 >>> id(b) 30984528 >>> c,d=3.1,3.1 >>> c is d False >>> id(c) 35058472 >>> id (d) 30984592 >>> c is not d True >>> a is not b False
Operator precedence
Operator precedence determines how an expression is evaluated. Certain operators have higher precedence than others; for example, the multiplication operator has higher precedence than the addition operator. In the expression x=7+3*2, x is assigned 13, not 20, because operator * has higher precedence than +, so it first multiplies 3*2 and then adds into 7.
Table 2-10 summarizes the operator’s precedence in Python, from lowest precedence to highest precedence (from top to bottom). Operators in the same box have the same precedence.
Table 2-10: Operator precedence
| Operator |
| not, or, and |
| in, not in |
| is, is not |
| =, %, =/, =//, -=, +=, *=, **= |
| <>, ==, != |
| <=, <, >, >= |
| ^, / |
| & |
| >>,<< |
| +/ – |
| *, /, %, // |
| ~,+, – |
| ** |
Delimiters
Delimiter is a character that separates and organizes items of data. An example of a delimiter is the comma character, which acts as a field delimiter in a sequence of comma-separated values. Table 2-11 provides a list of tokens which serves as delimiters in Python.
Table 2-11: Delimiters
| Delimiters | ||||||||||||
| ( | ) | [ | ] | @ | { | } | , | : | . | ‘ | ; | = |
| += | -= | *= | /= | //= | %= | &= | I= | ^= | >>= | <<= | **= | |
The following example shows how the use of delimeters can affect the result.
>>> 5+6/2 # no delimiter used 8.0 >>> (5+6)12 # delimiter used 5.5
Following are few points that a Python programmer should be aware of:
- The period (.) can also occur in floating-point and imaginary literals.
- The simple and augmented assignment operators, serve lexically as delimiters, but also perform operations.
- ASCII characters “, #, and \ have special meaning as part of other tokens or are otherwise significant to the lexical analyzer.
- Whitespace is not a token, but serve to delimit tokens.
Line structure
A Python program is divided into a number of logical lines.
Physical and logical lines
A physical line is a sequence of characters terminated by an end-of-line sequence. The end of a logical line is represented by the token NEWLINE. A logical line is ignored (i.e. no NEWLINE token is generated) that contains only spaces, tabs, or a comment. This is called “blank line”. The following code
>>> i=5 >>> print(5) 5
is same as:
>>> i=5; print (i) 5
A logical line is constructed from one or more physical lines by following the explicit or implicit line joining rules.
Explicit line joining
Two or more physical lines may be joined into logical lines using backslash characters (\), as shown in the following example:
>>>if 1900 < year < 2100 and 1 <= month <= 12 \ ... and 1 <= day <= 31 and 0 <= hour < 24 \ ... and 0 <= minute < 60 and 0 <= second < 60: . . . print year
A line ending in a backslash cannot carry a comment. Also, backslash does not continue a comment. A backslash does not continue a token except for string literals (i.e., tokens other than string literals cannot be split across physical lines using a backslash). A backslash is illegal elsewhere on a line outside a string literal.
>>> str='This is a \ ... string example' >>> str 'This is a string example' .
Implicit line joining
Expressions in parentheses, square brackets or curly braces can be split over more than one physical line without using backslashes. For example:
>>> month_names=['Januari','Februari','Maart', ... 'AprilMei','Juni', ... 'Juli','Augustus','September', ... 'Oktober','November','December'] # These are theDutch names for the months of the year
Implicitly continued lines can carry comments. The indentation of the continuation lines is not important. Blank continuation lines are allowed. There is no NEWLINE token between implicit continuation lines. Implicitly continued lines can also occur within triple-quoted strings; in that case they cannot carry comments.
>>> str="""This is ... a string ... example""" >>> str 'This is \na string \nexample' >>> str='''This is ... a string ... example''' >>> str 'This is \na string \nexample'
Comment
A comment starts with a hash character (#) that is not part of a string literal, and terminates at the end of the physical line. A comment signifies the end of the logical line unless the implicit line joining rules are invoked. Also, comments are not executed.
Indentation
Whitespace is important in Python. Actually, whitespace at the beginning of the line is important. This is called indentation. Leading whitespace (spaces and tabs) at the beginning of the logical line is used to determine the indentation level of the logical line, which in turn is used to determine the grouping of statements. This means that statements which go together must have the same indentation. Each such set of statements is a block. One thing should be remembered is Jhat wrong indentation can give rise to error (IndentationError exception).
>>> i=10 >>> print "Value is ",i Value is 10 >>> print "Value is ",i File "", line 1 print "Value is ",i IndentationError: unexpected indent
The indentation levels of consecutive lines are used to generate INDENT and DEDENT tokens. One can observe that by inserting whitespace in the beginning gave rise to IndentationError exception.
The following example shows non-uniform indentation is not an error.
>>> var=100 >>> if var!=100: ... print 'var does not have value 100' ... else: print 'var has value 100' var has value 100
Need for indentation
In C programming language, there are numerous ways to place the braces for grouping of statements. If a programmer is habitual of reading and writing code that uses one style, he or she will feel at least slightly uneasy when reading (or being required to write) another style. Many coding styles place begin/end brackets on a line by themselves. This makes programs considerably longer and wastes valuable screen space, making it harder to get a good overview of a program.
Guido van Rossum believes that using indentation for grouping is extremely elegant and contributes a lot to the clarity of the typical Python program. Since there are no begin/end brackets, there cannot be a disagreement between grouping perceived by the parser and the human reader. Also, Python is much less prone to coding-style conflicts.
Built-in types
This section describes the standard data types that are built into the interpreter. There are various built-in data types, for e.g., numeric, sequence, mapping, etc., but this book will cover few types. Schematic representation of various built-in types is shown in figure 2-1.
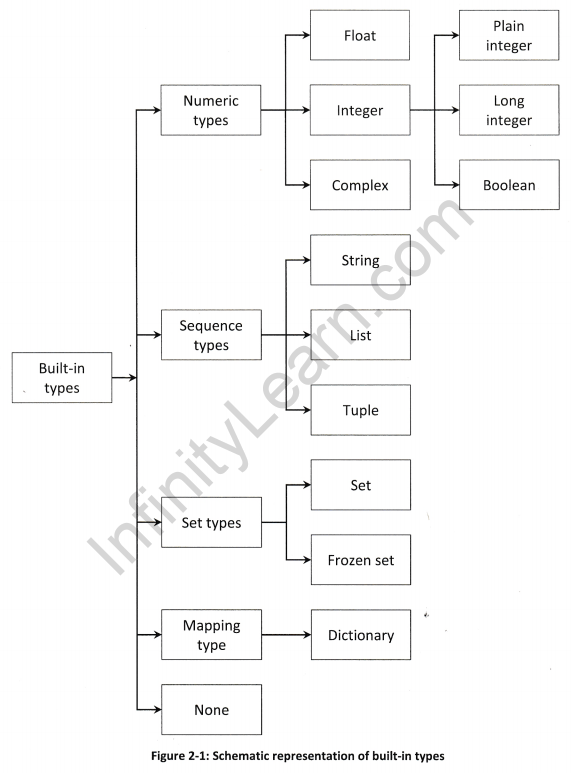
Numeric types
There are three distinct numeric types: integer, floating point number, and complex number.
Integer
Integer can be sub-classified into three types:
Plain integer
Plain integer (or simply “integer”) represents integer number in the range -2147483648 through 2147483647. When the result of an operation would fall outside this range, the result is normally returned as a long integer.
>>> a=2147483647 >>> type(a) <type 'int'> >>> a=a+1 >>> type(a) <type 'long'> >>> a=-2147483648 >>> type(a) <type 'int'> >>> a=a-1 >>> type(a) <type 'long'>
The built-in function int(x=0) convert a number or string x to an integer, or return 0, if no arguments are given.
>>> a='57' >>> type(a) <type 'str'> >>> a=int(a) >>> a 57 >>> type(a) <type 'int'> >>> a=5.7 >>> type(a) <type 'float'> >>> a=int(a) >>> a 5 >>> type(a) <type 'int'> >>> int () 0
Long integer
This represents integer numbers in virtually unlimited range, subject to available memory. The built-in function long (x=0) convert a string or number to a long integer. If the argument is a string, it must contain a possibly signed number. If no argument is given, OL is returned.
>>> a=5
>>> type(a)
<type 'int'>
>>> a=long(a)
>>> a
5L
>>> type(a)
<type 'long'>
>>> long()
OL
>>> long(5)
5L
>>> long(5.8)
5L
>>> long('5')
5L
>>> long('-5')
-5L
Integer literals with an L or 1 suffix yield long integers (L is preferred because 11 looks too much like eleven).
>>> a=10L >>> type(a) <type 'long'> >>> a=101 >>> type(a) <type 'long'>
The following expressions are interesting.
>>> import sys >>> a=sys.maxint >>> a 2147483647 >>> type(a) <type ' int'> >>> a=a+1 >>> a 2147483648L >>> type(a) <type 'long'>
Boolean
This represents the truth values False and True. The boolean type is a sub-type of plain integer, and boolean values behave like the values 0 and 1. The built-in function bool() convert a value to boolean, using the standard truth testing procedure.
>>> bool()
False
>>> a=5
>>> bool(a)
True
>>> bool ( 0)
False
>>> bool('hi')
True
>>> bool(None)
False
>>> bool('')
False
>>> bool(False)
False
>>> bool("False")
True
>>> bool(5>3)
True
Floating point number
This represents decimal point number. Python supports only double-precision floating point number (occupies 8 bytes of memory) and does not support single-precision floating point number (occupies 4 bytes of memory). The built-in function float () convert a string or a number to floating point number.
>>> a=57 >>> type (a) <type 'int'> >>> a=float(a) >>> a 57.0 >>> type(a) <type 'float'> >>> a='65' >>> type(a) <type 'str'> >>> a=float(a) >>> a 65.0 >>> type(a) <type 'float’> >>> a=le308 >>> a le+308 >>> type(a) <type 'float’> >>> a=1e309 >>> a inf >>> type (a) <type 'float'>
Complex number
This represents complex numbers having real and imaginary parts. The built-in function complex () is used to convert number or string to complex number.
>>> a=5.3 >>> a=complex(a) >>> a (5.3+0j) >>> type(a) ctype 'complex'> >>> a=complex() >>> a 0 j >>> type(a) <type 'complex'>
Appending j or J to a numeric literal yields a complex number.
>>> a=3.4j >>> a 3.4 j >>> type(a) <type 'complex'> >>> a=3.5+4.9j >>> type(a) <type 'complex'> >>> a=3.5+4.9J >>> type(a) <type 'complex'>
The real and imaginary parts of a complex number z can be retrieved through the attributes z . real and z . imag.
a=3.5+4.9J >>> a.real 3.5 >>> a.imag 4.9
Sequence Types
These represent finite ordered sets, usually indexed by non-negative numbers. When the length of a sequence is n, the index set contain the numbers 0, 1, . . ., n-1. Item i of sequence a is selected by a [ i ]. There are seven sequence types: string, Unicode string, list, tuple, bytearray, buffer, and xrange objects.
Sequence can be mutable or immutable. Immutable sequence is a sequence that cannot be changed after it is created. If immutable sequence object contains references to other objects, these other objects may be mutable and may be changed; however, the collection of objects directly referenced by an immutable object cannot change. Mutable sequence is a sequence that can be changed after it is created. There are two intrinsic mutable sequence types: list and byte array.
Iterable is an object capable of returning its members one at a time. Examples of iterables include all sequence types (such as list, str, and tuple) and some non-sequence types like diet and file etc. Iterables can be used in a for loop and in many other places where a sequence is needed (zip(), map (), …). When an iterable object is passed as an argument to the built-in function iter (), it returns an iterator for the object. An iterator is an object representing a stream of data; repeated calls to the iterator’s next () method return successive items in the stream. When no more data are available, Stoplteration exception is raised instead.
Some of the sequence types are discussed below:
String
It is a sequence type such that its value can be characters, symbols, or numbers. Please note that string is immutable.
>>> a='Python' : 2.7' >>> type(a) <type 'str'> >>> a[2] = 'S ' Traceback (most recent call last): File "", line 1, in TypeError: 'str' object does not support item assignment
The built-in function str (object=’ ‘ ) return a string containing a nicely printable representation of an object. For strings, this returns the string itself. If no argument is given, an empty string is returned.
>>> a=57.3 >>> type(a) <type 'float'> >>> a=str(a) >>> a '57.3' >>> type(a) <type 'str'>
Tuple
Tuple is comma-separated sequence of arbitrary Python objects enclosed in parenthesis (round brackets). Please note that tuple is immutable. Tuple is discussed in detail in chapter 4.
>>> a= (1,2,3,4) >>> type(a) <type 'tuple’> 'a', 'b', 'c')
List
List is comma-separated sequence of arbitrary Python objects enclosed in square brackets. Please note that list is mutable. More information on list is provided in chapter 4.
>>> a=[1,2,3,4] >>> type(a) <type 'list' >
Set types
These represent unordered, finite set of unique objects. As such, it cannot be indexed by any subscript, however they can be iterated over. Common uses of set are fast membership testing, removing duplicates from a sequence, and computing mathematical operations such as intersection, union, difference, and symmetric difference. There are two set types:
Set
This represents a mutable set. It is created by the built-in function set(), and can be modified afterward by several methods, such as add(), remove () etc. More information on set is given in chapter 4.
>>> set1=set() # A new empty set
>>> set1.add("cat") # Add a single member
>>> set1.update(["dog","mouse"]) # Add several members
>>> set1.remove("mouse") # Remove member
>>> set1
set(['dog', 'cat'])
>>> set2=set(["dog","mouse"])
>>> print set1&set2 # Intersection
set(['dog'])
>>> print setl|set2 # Union
set(['mouse', 'dog', 'cat'])
The set ( [ iterable ] ) return a new set object, optionally with elements taken from iterable.
Frozenset
This represents an immutable set. It is created by built-in function frozenset (). As a frozenset is immutable, it can be used again as an element of another set, or as dictionary key.
>>> frozenset() frozenset([])
>>> frozenset('aeiou')
frozenset(['a', 'i', 'e', 'u', 'o'])
>>> frozenset([0, 0, 0, 44, 0, 44, 18]) .
frozenset([0, 18, 44])
The frozenset ( [iterable] ) return return a new frozenset object, optionally with elements taken from iterable.
Mapping Types
This represents a container object that support arbitrary key lookups. The notation a [k] select the value indexed by key k from the mapping a; this can be used in expressions and as the target of assignments or del statements. The built-in function len () returns the number of items in a mapping. Currently, there is a single mapping type:
Dictionary
A dictionary is a mutable collection of unordered values accessed by key rather than by index. In dictionary, arbitrary keys are mapped to values. More information is provided in chapter 4.
>>> dictl={"john":34,"mike":56}
>>> diet1["michael"]=42
>>> dictl
{'mike': 56, 'john': 34, 'michael': 42}
>>> dictl["mike"]
56
None
This signifies the absence of a value in a situation, e.g., it is returned from a function that does not explicitly return anything. Its truth value is False.
Some other built-in types such as function, method, class, class instance, file, module etc. are discussed in later chapters.
Integer function
The following function operates on integer (plain and long).
int.bit_length()
Return the number of bits necessary to represent an integer (plain or long) in binary, excluding the sign and leading zeros.
>>>n=-3 7 >>> bin(n) # bin() convert integer number to a binary string >>> n.bit_length() 6 >>> n=2**31 >>> n 2147483648L >>> bin(n) 'Obi0000000000000000000000000000000' >>> n.bit_length() 32
Float functions
Some of the functions for floating point number are discussed below.
float.as_integer_ratio()
Return a pair of integers whose ratio is exactly equal to the original float and with a positive denominator.
>>> (-0.25).as_integer_ratio() (-1, 4)
float.is_integer()
Return True if the float instance is finite with integral value, otherwise it return False.
>>> (-2.0).is_integer() True >>> (3.2) .is_integer() False
String
Python can manipulate string, which can be expressed in several ways. String literals can be enclosed in matching single quotes (.’) or double quotes (“); e.g. ‘hello’, “hello” etc. They can also be enclosed in matching groups of three single or double quotes (these are generally referred to as triple- quoted strings), e.g. ‘ ‘ ‘hello’ ‘ ‘, “””hello”””. A string is enclosed in double quotes if the string contains a single quote (and no double quotes), else it is enclosed in single quotes.
>>> "doesnt" ’doesnt1 >>> "doesn't" "doesn't" >>> '"Yes," he said.' '"Yes," he said.'
The above statements can also be written in some other interesting way using escape sequences.
>>> "doesn\'t" t "doesn't" >>> '\"Yes,\" he said.' '"Yes," he said.'
Escape sequences are character combinations that comprises of a backslash (\) followed by some character, that has special meaning, such as newline, backslash itself, or the quote character. They are called escape sequences because the backslash causes an escape from the normal way characters are interpreted by the compiler/interpreter. The print statement produces a more readable output for such input strings. Table 2-12 mentions some of the escape sequences.
Table 2-12: Escape sequence
| Escape sequence | Meaning |
| \n | Newline. |
| \t | Horizontal tab. |
| \v | Vertical tab. |
| \\ | Backslash (\). |
| \’ | Single quote (‘). |
| \” | Double quote (“). |
String literal may optionally be prefixed with a letter r or R , such string is called raw string, and there is no escaping of character by backslash.
>>> str='This is \n a string' >>> print str This is a string >>> str=r'This is \n a string' >>> print str This is \n a string
Specifically, a raw string cannot end in a single backslash.
>>> str=r'\' File "", line 1 str=r '\' SyntaxError: EOL while scanning string literal
Triple quotes are used to specify multi-line string. One can use single quotes and double quotes freely within the triple quotes.
>>> line="""This is ... a triple ... quotes example""" >>> line 'This is\na triple\nquotes example' >>> print line *' This is a triple quotes example
Unicode strings are not discussed in this book, but just for the information that a prefix of ‘ u’ or ‘ U’ makes the string a Unicode string.
The string module contains a number of useful constants and functions for string based operations. Also, for string functions based on regular expressions, refer re module. Both string and re modules are discussed later in this chapter.
String operations
Some of the string operations supported by Python are discussed below.
Concatenation
Strings can be concatenated using + operator.
>>> word='Python'+' Program' >>> word 'Python Program'
Two string literals next to each other are automatically concatenated; this only works with two literals, not with arbitrary string expressions.
>>> 'Python' ' Program' 'Python Program' >>> wordl='Python' >>> word2='Program' >>> wordl word2 File "", line 1 wordl word2 SyntaxError: invalid syntax
Repetition
Strings can be repeated with * operator.
>>> word='Help ' >>> word*3 'Help Help Help ' >>> 3*word 'Help Help Help '
Membership operation
As discussed previously, membership operators in and not in are used to test for membership in a sequence.
>>> word= ' Python ' >>> 'th' in word True >>> 'T' not in word True
Slicing operation
String can be indexed, the first character of a string has sub-script (index) as 0. There is no separate character type; a character is simply a string of size one. A sub-string can be specified with the slice notation.
>>> word='Python' >>> word[2] ' t' >>> word [0:2] 'Py'
String slicing can be in form of steps, the operation s [ i : j : k ] slices the string s from i to j with step k.
>>> word[1:6:2] ' yhn'
Slice indices have useful defaults, an omitted first index defaults to zero, an omitted second index defaults to the size of the string being sliced.
>>> word[:2] 'Py' >>> word[2:] 'thon'
As mentioned earlier, string is immutable, however, creating a new string with the combined content is easy and efficient.
>>> word[0]='J' Traceback (most recent call last): File "", line 1, in TypeError: 'str' object does not support item assignment >>> 'J'+word[1:] 'Jython'
If upper bound is greater than length of string, then it is replaced by the string size; an upper bound smaller than the lower bound returns an empty string.
>>> word[2:50] 'thon' >>> word [4:1] ' '
Indices can be negative numbers, which indicates counting from the right hand side.
>>> word[-l] 'n' >>> word[-2] ' o' >>> word[-3:] ' hon' >>>. word [ : -3 ] 'Pyt' >>> word[-0] # -0 is same as 0 'p.
Out of range negative slice indices are truncated, but single element (non-slice) index raises IndexError exception.
>>> word[-100:] 'Python' >>> word[-100] Traceback (most recent call last): File "", line 1, in IndexError: string index out of range
String formatting
String objects has an interesting built-in operator called modulo operator (%). This is also known as the “string formatting” or “interpolation operator”. Given format%values (where format is a string object), the % conversion specifications in format are replaced with zero or more elements of values. The % character marks the start of the conversion specifier. If format requires a single argument, values may be a single non-tuple object. Otherwise, values must be a tuple with exactly the number of items specified by the format string, or a single mapping object (a dictionary). If dictionary is provided, then the mapping key is provided in parenthesis.
>>> '%s Python is a programming language.' % 'Python'
'Python Python is a programming language.'
>>> '%s Python is a programming language.' % ('Python')
'Python Python is a programming language.'
>>>
>>> '%s has %d quote types.' % ('Python',2)
'Python has 2 quote types.'
>>> '%s has %03d quote types.' % ('Python',2)
'Python has 002 quote types.'
>>> '%(language)s has %(number)03d quote types.' % \
... {"language":"Python","number":2}
'Python has 002 quote types.'
In the above example, 03 consists of two components:
- 0 is a conversion flag i.e. the conversion will be zero padded for numeric values.
- 3 is minimum field width (optional).
Table 2-13 shows some of the conversion types.
Table 2-13: Conversion types
| Conversion | Meaning |
| D | Signed integer decimal. |
| I | Signed integer decimal. |
| E | Floating point exponential format (lowercase). |
| E | Floating point exponential format (uppercase). |
| F | Floating point decimal format. |
| F | Floating point decimal format. |
| g | Floating point format. Uses lowercase exponential format if exponent is less than -4 or not less than precision, decimal format otherwise. |
| G | Floating point format. Uses uppercase exponential format if exponent is less than -4 or not less than precision, decimal format otherwise. |
| S | String. |
Precision (optional) is given as a dot (.) followed by the precision number. While using conversion type f, F, e, or E, the precision determines the number of digits after the decimal point, and it defaults to 6.
>>>"Today's stock price :%f" % 50 "Today's stock price: 50.00000 >>> "Today's stock price :%F" % 50 "Today's stock price: 50.000000 >>> >>> "Today's stock price :%f" % 50.4625 "Today's stock price: 50.462500" >>> "Today's stock price :%F" % 50.4625 "Today's stock price: 50.462520" >>> >>> "Today's stock price :%.2f" % 50.46251987624312359 "Today's stock price: 50.46 >>> "Today's stock price :%.2F" % 50.46251987624312359 "Today's stock price: 50.46 >>> >>> "Today's stock price: %e" % 50.46251987624312359 "Today's stock price: 5.046252e+01" >>> "Today's stock price: %E" % 50.46251987624312359 "Today's stock price: 50.046252E+01" >>> >>> "Today's stock price: %.3e" % 50.46251987624312359 "Today's stock price: 5. 046e+01" >>> "Today's stock price: %.3E" % 50.46251987624312359 "Today's stock price: 5. 046E+01"
While using conversion type g or G, the precision determines the number of significant digits before and after the decimal point, and it defaults to 6.
>>> "Today's stock price: %g" % 50.46251987624312359 "Today's stock price: 50.4625" >>> "Today's stock price: %G" % 50.46251987624312359 - "Today's stock price: 50.4625" >>> >>> "Today's stock price: %g" % 0.0000005046251987624312359 "Today's stock price: 5.04625e-07" >>> "Today's stock price: %G" % 0.0000005046251987624312359 "Today's stock price: 5.04625E-07"
String constants
Some constants defined in string module are as follows:
string.ascii_lowercase
It returns string containing lowercase letters ‘ abcdefghi jklmnopqrstuvwxyz ‘.
>>> import string >>> string.ascii_lowercase 'abcdefghijklmnopqrstuvwxyz'
string. ascii__uppercase
It return string containing uppercase letters ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ ‘.
>> string.ascii_uppercase 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
string.ascii_letters
It returns string containing concatenation of the ascii_lowercase and ascii_uppercase constants.
>>> string.ascii_letters 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
string.digits
It returns the string containing digits ‘ 0123456789 ‘.
>> string.digits ' 0123456789'
string.hexdigits
It returns the string containing hexadecimal characters ‘ 0123 456 78 9abcdef ABCDEF ‘.
>>> string.hexdigits '0123456789abcdefABCDEF'
string.octdigits
It returns the string containing octal characters ‘01234567’.
>>> string.octdigits '01234567'
string.punctuation
It returns the string of ASCII characters which are considered punctuation characters.
>>> string. punctuation
' ! "#$%&V ()* + ,-./: ;<=>?@ [\\] A_' { |
string.whitespace
It returns the string containing all characters that are considered whitespace like space, tab, vertical tab etc.
>>> string.whitespace '\t\n\x0b\x0c\r '
string.printable
It returns the string of characters which are considered printable. This is a combination of digits, letters, punctuation, and whitespace.
>>> string.printable
'01234567 8 9abcdefghij klmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%& V()*+,-./:;<=>?©[\\]A_'{I\t\n\r\x0b\x0c’
String methods
Below are listed some of the string methods which supports both strings and Unicode objects. Alternatively, some of these string operations can also be accomplished using functions of string module.
str.isalnum()
Return True, if all characters in the string are alphanumeric, otherwise False is returned.
>>> str="this2009" >>> str.isalnum() True >>> str="this is string example....wow!!!" >>> str.isalnum() False
str.isalpha()
Return True, if all characters in the string are alphabetic, otherwise False is returned.
>>> str="this" >>> str.isalpha() True >>> str="this is string example .... wow!!!" >>> str.isalpha() , False
striisdigit()
Return True, if all characters in the string are digits, otherwise False is returned.
>>> str="this2009 >>> str.isdigit() False >>> str="2009" >>> str.isdigit() True
str.isspace()
Return True, if there are only whitespace characters in the string, otherwise False is returned.
>>> str=" " >>> str.isspace () True >>> str="This is string example .... wow!!!" >>> str.isspace () False
str.islower()
Return True, if all cased characters in the string are in lowercase and there is at least one cased character, False otherwise.
>>> str="THIS is string example....wow!!!" >>> str.islower() False >>> str="this is string example .... wow!!!" >>> str.islower() True >>> str="this2009" >>> str.islower() True >>> str="2009" >>> str.islower() False
str.lower()
Return a string with all the cased characters converted to lowercase.
>>> str="THIS IS STRING EXAMPLE .... WOW!!!" >>> str.lower() 'this is string example....wow!!!'
The above can be imitated using string module’s function string. lower (s), where s is a string.
>>> import string >>> str="THIS IS STRING EXAMPLE .... WOW!!!" - >>> string.lower(str) 'this is string example....wow!!!'
str.isupper ()
Return True, if all cased characters in the string are uppercase and there is at least one cased character, otherwise False is returned.
>>> str="THIS IS STRING EXAMPLE .... WOW!!!" >>> str.isupper() True >>> str="THIS is string example .... wow!!!" >>> str.isupper () False
str.upper ()
Return a string with all the cased characters converted to uppercase. Note that str . upper () . isupper () might be False, if string contains uncased characters.
>>> str="this is string example .... wow!!!" >>> str.upper() 'THIS IS STRING EXAMPLE....WOW!!!' >>> str.upper () .isupper() True >>> str="012340" >>> str.upper() ' 012340' >>> str.upper().isupper() False
The above can be imitated using string module’s function string. upper (s), where s is a string.
>>> str="this is string example .... wow!!!" >>> string.upper(str) 'THIS IS STRING EXAMPLE....WOW!!!' >>> string.upper(str).isupper() t True . >>> str="012340" >>> string.upper(str) '012340' >>> string.upper(str).isupper() False
str.capitalize()
Return a string with its first character capitalized and the rest lower cased.
>>> str="this Is stRing example .... wow!!!" - >>> str.capitalize() 'This is string example....wow!!!'
The above can be imitated using string module’s function string. capitalize (word), where word is a string.
>>> str="this Is stRing example....wow!!!" >>> string.capitalize(str) 'This is string example....wow!!!'
str.istitle ()
Return True, if the string is title cased, otherwise False is returned.
>>> str="This Is String Example ... Wow!!!" >>> str.istitle () True >>> str="This is string example .... wow!!!" >>> str.istitle() False
str.title ()
Return a title cased version of the string, where words start with an uppercase character and the remaining characters are lowercase. It will return unexpected result in cases where words have apostrophe etc.
>>> str="this is string example .... wow!!!" >>> str.title() 'This Is String Example....Wow!!!' >>> str="this isn't a float example .... wow!!!" >>> str.title () "This Isn'T A Float Example .... Wow!!!"
str.swapcase()
Return a copy of the string with reversed character case.
>>> str="This is string example .... WOW!!! " >>> str.swapcase() 'tHIS IS STRING EXAMPLE ... .wow! !! '
The above can be imitated using string module’s function string. swapcase (s), where s is a string.
>>> str="This is string example .... WOW!!!" >>> string.swapcase(str) 'tHIS IS STRING EXAMPLE....wow!!!' '
str.count(sub[,start[,end]])
Return the number of non-overlapping occurrences of sub-string sub in the range [start, end]. Optional arguments start and end are interpreted as in slice notation.
>>> str="this is string example .... wow!!!" >>> sub="i" >>> str.count(sub,4,40) 2 >>> sub="wow" >>> str.count(sub) 1
The above can be imitated using string module’s function string. count (s, sub [, start [, end] ] ), where s is a string.
>>> str="this is string example .... wow!!!" >>> sub="i" >>> string.count(str,sub,4,40) 2 >>> sub="wow" >>> string.count(str,sub) 1
str.find(sub[,start[,end]])
Return the lowest index in the string where sub-string sub is found, such that sub is contained in the slice s [ start: end]. Optional arguments start and end are interpreted as in slice notation. Return -1, if sub is not found.
>>> str1 = "this is string example .... wow! !!" >>> str2="exam" >>> str1.find(str2) 15 >>> str1.find(str2,10) 15 >>> strl.find(str2,40) -1
The above can be imitated using string module’s function string, find (s, sub [, start [, end] ] ), where s is a string.
>>> str1="this is string example .... wow!!!" >>> str2="exam" >>> string.find(str1,str2) 15 >>> string.find(strl,str2,10) 15 >>> string.find(strl,str2,40) -1
The find () method should be used only if there is a requirement to know the position of sub. To check if sub is a sub-string or not, use the in operator:
>>> 'Py' in 'Python' True
str.rfind(sub[,start[, end]])
Return the highest index in the string where sub-string sub is found, such that sub is contained within s [start: end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure.
>>> str1="this is really a string example....wow!!!" >>> str2="is" >>> str1.rfind(str2) 5 >>> str1.rfind(str2,0,10) 5 >>> strl.rfind(str2,10,20) -1
The above can be imitated using string module’s function string. rf ind (s, sub [, start [, end] ] ), where s is a string.
>>> str1 = "this is really a string example.... wow!!!" >>> str2="is" >>> string.rfind(str1,str2) 5 >>> string.rfind(str1,str2,0,10) 5 >>> string.rfind(str1,str2,10,0) -1
str.index(sub[,start[,end]])
Like find (), but raise ValueError when the sub-string is not found.
>>> str1="this is string example....wow!!!" >>> str2="exam" >>> str1.index(str2) 15 >>> str1.index(str2,10) . 15 >>> str1.index(str2,40) Traceback (most recent call last): File "<pyshell#38>", line 1, in str1.index(str2, 40) ValueError: substring not found
The above can be imitated using string module’s function string. index (s, sub [, start i [, end] ] ), where s is a string.
>>> strl = "this is string example .... wow!!!" >>> str2 = "exam" >>> string.index(strl,str2) 15 >>> string.index(strl,str2,10) 15 >>> string.index(strl,str2,40) Traceback (most recent call last): File "", line 1, in File "C:\Python27\lib\string.py", line 328, in index return s.index(*args) ValueError: substring not found
str.rindex(sub[,start[,end]])
Like rf ind (), but raises ValueError when the sub-string sub is not found.
>>> strl="this is string example....wow!!!" >>> str2="is" >>> strl.rindex(str2) 5 >>> str1.rindex(str2,10,20) Traceback (most recent call last): File "", line 1, in ValueError: substring not found
The above can be imitated using string module’s function string. rf ind (s, sub [, start [, end] ] ), where s is a string.
>>> strl = "this is string example .... wow!!!" >>> str2="is" >>> string.rindex(strl,str2) 5 >>> string.rindex(strl,str2,10,20) Traceback (most recent call last): File "", line 1, in File "C:\Python27\lib\string.py", line 337, in rindex return s.rindex(*args) ValueError: substring not found
str.startswith(prefix[,start[,end]])
Return True, if string start with the prefix, otherwise return False. The prefix can also be a tuple of prefixes to look for. With optional start, test string beginning at that position. With optional end, stop comparing string at that position.
>>> str="this is string example .... wow!!!" .
>>> str.startswith(1 this 1)
True
>>> str.startswith('is',2)
True
>>> str.startswith('this',10,17)
False
>>> pfx=('the','where' ,'thi')
>>> str.startswith(pfx)
True
str.endswith(suffix[,start[,end]])
Return True, if the string ends with the specified suffix, otherwise return False. The suffix can also be a tuple of suffixes to look for. The test starts from the index mentioned by optional argument start. The comparison is stopped indicated by optional argument end.
>>> str="this is string example .... wow!!!" >>> suffix="wow!!!" >>> str.endswith(suffix) True >>> suf f ix= ( "tot! ! ! " , "wow !!.!") >>> str.endswith(suffix) True >>> str.endswith(suffix,20) True • >>> suffix="is" >>> str.endswith(suffix,2,4) True >>> str.endswith(suffix,2,6) False >>> str . endswith ( ( ' hey ' , ' bye w!.!!.'):) True
str.join(iterable)
Return a string which is the concatenation of the strings in the iterable iterable. The separator between elements is the string str providing this method.
>>> str="-"
>>> seq=("a" , "b" , "c" ) s
>>> str.join(seq) ,
'a-b-c'
»> seq= [ "a" , "b" , "c" ]
>>> str.join(seq)
'a-b-c'
The above can be imitated using string module’s function string, join (words [, sep] ), where words is a list or tuple of strings, while default value for sep is a single space character.
>>> str="-"
>>> seq=("a","b","c") -
>>> string.join(seq,str)
'a-b-c'
»> seq= [ "a" , "b" , "c" ]
>>> string.join(seq,str)
'a-b-c'
str.replace(old,new [,count])
Return a string with all occurrences of sub-string old replaced by new. If the optional argument count is given, only the first count occurrences are replaced.
>>> str="this is string example.... wow!! ! this is really string"
>>> str.replace("is ","was")
'thwas was string example.... wow!! ! thwas was really string'
>>> str="this is string example....wow!!! this is really string"
>>> str.replace("is","was",3)
'thwas was string example....wow!!! thwas is really string'
The above can be imitated using string module’s function string, replace (s, old, new [, maxreplace ] ), where s is a string and maxreplace is same as count (discussed above).
>>> str="this is string example.... wow!! ! this is really string" >>> string.replace(str,"is","was") 'thwas was string example.... wow!! ! thwas was really string' >>> str="this is string example.... wow!! ! this is really string" >>> string.replace(str,"is","was", 3) 'thwas was string example.... wow!! ! thwas is really string'
str.center(width[,fillchar])
Return centered string of length width. Padding is done using optional argument f illchar (default is a space).
>>> str="this is string example .... wow!!!" >>> str.center(40,'a') 'aaaathis is string example....wow!!!aaaa' >>> str="this is string example .... wow!!!" >>> str.center(40) ' this is string example....wow!!! '
The above can be imitated using string module’s function stping. center (s, width [, f illchar ] ), where s is a string.
>>> str="this is string example....wow!!!" >>> string.center(str,40,'a') 'aaaathis is string example....wow!!!aaaa' >>> str="this is string example .... wow!!!" >>> string.center(str,40) ' this is string example....wow!!!'
str.ljust(width),fillchar])
Return the string left justified in a string of length width. Padding is done using the optional argument fillchar (default is a space). The original string is returned if width is less than or equal to
len(str).
>>> str="this is string example .... wow!!!" >>> str.1 just(50, 10 ' ) 'this is string example ... .wow! !!000000000000000000' >>> str="this is string example .... wow!!!" >>> str.1just(50) 'this is string example....wow!!! ' >>> str="this is string example .... wow!!!" >>> str.1just(10) 'this is string example....wow!!!'
The above can be imitated using string module’s function string. 1 just (s, width [, f illchar ] ), where s is a string.
>>> str="this is string example....wow!!!" >>> string.1just(str,50, ’ 0 ' ) 'this is string example ....wow!!!000000000000000000' >>> str="this is string example....wow!!!" >>> string.1just(str,50) 'this is string example....wow!!! '
str.rjust(width[,fillchar])
Return the right justified string of length width. Padding is done using the optional argument fillchar (default is a space). The original string is returned if width is less than or equal to len ( str).
>>> str="this is string example .... wow!!!" >>> str.rjust(50,'0') 'OOOOOOOOOOOOOOOOOOthis is string example....wow!!!' >>> str="this is string example....wow!!!" >>> str.rjust (10, '0 ' ) 'this is string example....wow!!!'
The above can be imitated using string module’s function string.r just (s, width [, fillchar]), where s is a string.
>>> str="this is string example .... wow!!!" >>> string.rjust(str,50,' 0') '000000000000000000this is string example....wow!!!' >>> str="this is string example .... wow!!!" >>> string.rjust(str,10,'0') 'this is string example....wow!!!'
str.zfill(width)
Return a string of length width, having leading zeros. The original string is returned, if width is less than or equal to len (str).
>>> str="this is string example .... wow!!!" >>> str.zfill ( 40) 'OOOOOOOOthis is string example....wow!!!' >>> str . zf ill ( 45) 'OOOOOOOOOOOOOthis is string example....wow!!!'
The above can be imitated using string module’s function string. zfill (s, width), where s is a string.
>>> str="this is string example....wow!!!" >>> string.zfill(str,40) 'OOOOOOOOthis is string example....wow!!!' >>> string.zfill(str,45) 'OOOOOOOOOOOOOthis is string example....wow!!!' str.strip([chars])
Return a string with the leading and trailing characters removed. The chars argument is a string specifying the set of characters to be removed. If omitted or None, the chars argument defaults to removing whitespace.
>>> str="OOOOOOOthis is string example... .wow! !!0000000"
>>> str.strip ('0')
'this is string example....wow!!!'
The above can be imitated using string module’s function string . strip ( s [, chars ] ), where s is a string.
>>> str="OOOOOOOthis is string example .... wow!!!0000000" >>> string.strip(str,'0') 'this is string example....wow!!!'
str.lstrip([chars])
Return a string with leading characters removed. The chars argument is a string specifying the set of characters to be removed. If omitted or None, the chars argument defaults to removing whitespace.
>>> str=" this is string example. . . .wow! ! ! "
>>> str.lstrip()
'this is string example....wow!!! '
>>> str="88888888this is string example .... wow!!!8888888"
>>> str.lstrip('8')
'this is string example ....wow! !! 8888888'
The above can be imitated using string module’s function string. lstrip (s [, chars ]), where s is a string.
>>> str=" this is string example....wow!!! " . >>>string.lstrip(str) 'this is string example....wow!!! ' >>> str="88888888this is string example .... wow!!!8888888" >>> string.lstrip(str,'8') 'this is string example ....wow! !! 8888888 '
str.rstrip([chars])
Return a string with trailing characters removed. The chars argument is a string specifying the set of characters to be removed. If omitted or None, the chars argument defaults to removing whitespace.
>>> str=" this is string example....wow!!! "
>>> str.rstrip()
' this is string example....wow!!!'
>>> str="88888888this is string example .... wow!!!8888888"
>>> str.rstrip('8')
'88888888this is string example .... wow!!! '
The above can be imitated using string module’s function string. rstrip (s [, chars ]), where s is a string.
>>> str=" this is string example....wow!!! " >>> string.rstrip(str) ' this is string example....wow!!!' >>> str="88888888this is string example .... wow!!!8888888" >>> string.rstrip(str,'8') '88888888this is string example....wow!!!'
str.partition(sep)
Split the string at the first occurrence of sep, and return a tuple containing the part before the separator, the separator itself, and the part after the separator.
>>> str=" this is string example .... wow!! ! "
>>> str.partition('s')
(' thi', 's', ' is string example .... wow!! ! ')
str.rpartition(sep)
Split the string at the last occurrence of sep, and return a tuple containing the part before the separator, the separator itself, and the part after the separator.
>>> str=" this is string example....wow!!! "
>>> str.rpartition('s')
(' this is ', 's', 'tring example.... wow!! ! ')
str.split([sep[,maxsplit]])
Return a list of the words from the string using sep as the delimiter string. If maxsplit is given, at most maxsplit splits are done (thus, the list will have at most maxsplit+1 elements). If maxsplit is not specified or -1, then all possible splits are made. If sep is not specified or None, any whitespace string is a separator.
>>> str="Linel-abcdef \nLine2-abc \nLine4-abcd"
>>> str.split()
['Linel-abcdef', 'Line2-abc', 'Line4-abcd']
>>> str.split(' ',1)
['Linel-abcdef', '\nLine2-abc \nLine4-abcd']
The above can be imitated using string module’s function string. split (s [, sep [, maxsplit ] ] ), where s is a string.
>>> str="Linel-abcdef \nLine2-abc \nLine4-abcd" >>> string.split(str) ['Linel-abcdef', 'Line2-abc', 'Line4-abcd'] >>> string.split(str,' ',1) ['Linel-abcdef', '\nLine2-abc \nLine4-abcd']
str.rsplit([sep[,maxsplit]])
Return a list of the words from the string using sep as the delimiter string. If maxsplit is given, at most maxsplit splits are done, the rightmost ones. If sep is not specified or None, any whitespace string is a separator. Except for splitting from the right, rsplit () behaves like split () which is described in detail below.
>>> str=" this is string example....wow!!! "
>>> str.rsplit()
['this', 'is', 'string', 'example .... wow!!!']
>>> str.rsplit('s') '
[' thi', ' i', ' ', 'tring example.... wow!! ! ']
The above can be imitated using string module’s function string. rsplit (s [, sep [, maxsplit] ] ), where s is a string.
>>> str=" this is string example .... wow!! ! >>> string.rsplit(str) ['this', 'is', 'string', 'example .... wow!!!'] >>> string.rsplit(str,'s') [' thi', ' i', ' ', 'tring example.... wow!! !
str.splitlines([keepends])
Return a list of the lines in the string, breaking at line boundaries. Line breaks are not included in the resulting list unless keepends is given.
>>> str="Linel-a b c d e f\nLine2- a b c\n\nLine4- abed" >>> str.splitlines() ['Linel-a b c d e f', 'Line2- a b c', '', 'Line4- a b c d'] >>> str.splitlines(0) ['Linel-a b c d e f', 'Line2- a b c', '', 'Line4- a b c d'] >>> str.splitlines(False) ['Linel-a b c d e f', 'Line2- a b c', '', 'Line4- a b c d'] . >>> str.splitlines(1) ['Linel-a b c d e f\n', 'Line2- a b c\n', '\n', 'Line4- a b c d'] >>> str.splitlines(True) ['Linel-a b c d e f\n', 'Line2- a b c\n', '\n', 'Line4- a b c d']
str.translate(table[,deletechars])
Return a string having all characters occurring in the optional argument deletechars are removed, and the remaining characters have been mapped through the given translation table, which must be a string of length 256.
The maketransO function (discussed later in this section) from the string module is used to create a translation table. For string objects, set the table argument to None for translations that only delete characters.
>>> str='this is string example....wow!!!'
>>> tab=string.maketrans('e','E')
>>> str.translate(tab)
'this is string ExamplE....wow!!!'
>>> str.translate(tab,'ir')
'ths s stng ExamplE....wow!!!'
>>> str.translate(None,'ir')
'ths s stng example....wow!!!'
The above can be imitated using string module’s function string. translate (s, table [, deletechars ] ), where s is a string.
>>> str='this is string example....wow!!!'
>>> tab=string.maketrans('e','E')
>>> string.translate(str,tab)
'this is string ExamplE....wow!!!'
>>> string.translate(str,tab,'ir')
'ths s stng ExamplE....wow!!!'
>>> string.translate(str,None,'ir')
'ths s stng example....wow!!!'
The following functions are there in string module, but are not available as string methods.
string. capwords (s [, sep] )
Split the argument s into words using str. split (), then capitalize each word using str . capitalize (), and join the capitalized words using str . join (). If the optional second argument sep is absent or None, runs of whitespace characters are replaced by a single space and leading and trailing whitespace are removed, otherwise, sep is used to split and join the words.
>>> str=" this is string example.... wow!!! >>> string.capwords(str) 'This Is String Example.... Wow!!!' >>> string.capwords(str,' ') ' This Is String Example.... Wow!!! ' >>> string.capwords(str,'s') ' this is sTring example.... wow!!! '
string.maketrans(from, to)
Return a translation table suitable for passing to translate (), that will map each character in from into the character at the same position in to, from and to must have the same length.
>>> str='this is string example....wow!!!'
>>> tab=string.maketrans('t!' ,'T.')
>>> string.translate(str,tab)
'This is sTring example....wow...'
>>> string.translate(str,tab,'ir')
'Ths s sTng example....wow...'
>>> string.transiate(str,None,'ir')
'ths s stng example....wow!!!'
Regular expression module
Regular expression (also called RE, or regex, or regex pattern) is a specialized approach in Python, using which programmer can specify rules for the set of possible strings that needs to be matched; this set might contain english sentences, e-mail addresses, or anything. REs can also be used to modify a string or to split it apart in various ways.
Meta characters
Most letters and characters will simply match themselves. For example, the regular expression test will match the string test exactly. There are exceptions to this rule; some characters are special “meta characters”, and do not match themselves. Instead, they signal that some out-of-the-ordinary thing should be matched, or they affect other portions of the RE by repeating them or changing their meaning. Some of the meta characters are discussed below:
Table 2-14: Meta characters
| Meta character | Description | Example |
| [] | Used to match a set of characters. | [time]
The regular expression would match any of the characters t, i, m or e. [a-z] The regular expression would match only lowercase characters. |
| ^ | A Used to complement a set of characters. | [^time] The regular expression would match any other characters than t, /’, m or e. |
| $ | Used to match the end of string only. | time$ The regular expression would match time in ontime, but will not match time in timetable. |
| * | Used to specify that the previous character can be matched zero or more times. | tim *e The regular expression would match strings like timme, tie and so on. |
| + | Used to specify that the previous character can be matched one or more times. | tim+e The regular expression would match strings like timme, timmme, time and so on. |
| ? | Used to specify that the previous character can be matched either once or zero times. | tim ?e The regular expression would only match strings like time or tie. |
| {} | The curly brackets accept two integer values. The first value specifies the minimum number of occurrences and second value specifies the maximum of occurrences. | tim{1,4}e The regular expression would match only strings time, timme, timmme or timmmme. |
Regular expression module functions
Some of the methods of re module as discussed below:
re.compile(pattern)
The function compile a regular expression pattern into a regular expression object, which can be used for matching using its match () and search () methods, discussed below.
>>> import re
>>> p=re.compile('tim*e')
re.match(pattern,string)
If zero or more characters at the beginning of string match the regular expression pattern, match () return a corresponding MatchObject instance. The function returns None, if the string does not match the pattern.
re.group()
The function return the string matched by the RE.
>>> m=re.match('tim*e','timme pass time')
>>> m.group()
'timme'
The above patch of code can also be written as:
>>> p=re.compile('tim*e')
>>> m=p.match('timme pass timme')
>>> m.group()
'timme'
re.search(pattern,string)
The function scans through string looking for a location where the regular expression pattern produces a match, and return a corresponding MatchObject instance. The function returns None, if no position in the string matches the pattern.
>>> m=re.search('tim*eno passtimmmeee1)
>>> m.group()
'timmme'
The above patch of code can also be written as:
>>> p=re.compile('tim*e')
>>> m=p.search('no passtimmmeee')
>>> m.group()
'timmme'
re.start()
The function returns the starting position of the match.
re.end()
The function returns the end position of the match.
re.span()
The function returns a tuple containing the (start, end) indexes of the match.
>>> m=re.search('tim*e','no passtimmmeee')
>>> m.start()
7
>>> m.end()
13
>>> m.span()
(7, 13)
The above patch of code can also be written as:
>>> p=re.compile('tim*e')
>>> m=p.search('no passtimmmeee')
>>> m.start()
7
>>> m.end()
13
>>> m.span()
(7, 13)
re.findall(pattern,string)
The function returns all non-overlapping matches of pattern in string, as a list of strings. The string is scanned left-to-right, and matches are returned in the order found.
>>> m=re.findall('tim*e','timeee break no pass timmmeee')
>>> m
['time', 'timmme']
The above patch of code can also be written as:
>>> p=re.compile('tim*e')
>>> m=p.findall('timeee break no pass timmmeee')
>>> m
['time', 'timmme']
re.finditer(pattern,string)
The function returns an iterator yielding MatchObject instances over all non-overlapping matches for the RE pattern in string. The string is scanned left-to-right, and matches are returned in the order found.
>>> m=re.finditer('tim*etimeee break no pass timmmeee')
>>> for match in m:
... print match.group()
... print match.span()
time
(0, 4)
timmme
(21, 27)
The above patch of code can also be written as:
>>> p=re.compile('tim*e')
>>> m=p.finditer('timeee break no pass timmmeee')
>>> for match in m:
... print match.group()
... print match.span()
time (0, 4) timmme (21, 27)
Error
An error (or software bug) is a fault in a computer program that produces incorrect or unexpected result, or causes it to behave in unintended ways. Mostly bug arise from mistakes and errors made by people in either a program’s source code or its design. Usually, errors are classified as: syntax error, run-time error and logical error.
Syntax error
Syntax error refers to an error in the syntax of tokens and/or sequence of tokens that is intended to be written in a particular programming language. For compiled languages, syntax errors occur strictly at compile-time. A program will not compile until all syntax errors are corrected. For interpreted languages, however, not all syntax errors can be reliably detected until run-time.
>>> prin 'Hi' SyntaxError: invalid syntax >>> print "Hi' SyntaxError: EOL while scanning string literal
Run-time error
Run-time error is an error which can be detected during the execution of a program. The code appears to be correct (it has no syntax errors), but it will not execute. For example, if a programmer has written a correct code to open a file using open () function, and if the file is corrupted, the application cannot carry out the execution of open () function, and it stops running.
Logical error
Logical error (or semantic error) is a bug in a program that causes it to operate incorrectly, but not terminate abnormally. A logical error produces unintended or undesired output or other behavior, although it may not immediately be recognized. Logic error occurs both in compiled and interpreted languages. Unlike a program with a syntax error, a program with a logical error is a valid program in the language, though it does not behave as intended. The only clue to the existence of logic errors is the production of wrong solutions. For example, if a program calculates average of variables a and b, instead of writing the expression c= (a+b) /2, one can write c=a+b/2, which is a logical error.
>>> print a+b/2 6.5 >>> print (a+b)/2 5.0
