
CBSE Class 12 Informatics Practices Notes Chapter 10 Fundamentals of Database
Why Use a Database?
Databases are most useful when it comes to storing information that fits into logical categories, e.g. if you want to store information of all the employees in a company. With a database, you can group different parts of your business into separate tables to help store your information logically, i.e. tables might be Employees, Supervisors and Customers. Each table would then contain columns specific to these three areas. To help store information related to each employee, the Employees table might have the columns Hiring Date, Position, Age and Salary. So in this, we use a database that stores data in logical manner through which we can retrieve them conveniently and efficiently.
Data Models
A data model is a collection of concepts that can be used to describe the structure of a database and also provides a collection of high level data description constructs that hide many low level storage details.
Three types of data models are:
- Network Data model
- Hierarchical Data model
- Relational Data model.
In a network data model, data is represented by collection of records and relationships among data are represented as links. While in hierarchical data model, records are organised as trees. So, hierarchical database is a collection of records connected to one another through links.
In a relational data model, there are tables that store data. The columns define which kind of information will be stored in the table. An individual column must be created for each type of data you wish to store (i.e. Age, Weight, Height). On the other hand, a row contains the actual values for these specified columns. Each row will have one value for each and every column, e.g. a table with columns (Name, Age, Weight-lbs) could have a row with the values (Bob, 65, 165).
Database Management System (DBMS)
A Database Management System is a set of programs that enables users to define, create and maintain the database and provides controlled access to this database. DBMS is the combination of two words data base + management system. The primary goal of a DBMS is to provide a way to store and retrieve database information that is both convenient and efficient.
Data in a database can be added, deleted, changed, sorted or searched, etc., using a DBMS. e.g. MySQL, lngers, MS-Access, Oracle, etc., are the most popular DBMS softwares. The purpose of a DBMS is to bridge the gap between the information and data. The data stored in memory or on a disk must be converted to usable information.
Relational Database Management System (RDBMS)
A Relational Database Management System (RDBMS) is a database management system. It is developed by Dr. E.F Codd, of IBM’s SAN Jose Research Laboratory. RDBMS stores data in the form of related tables. RDBMS are powerful because they require few assumptions about how data is related or how it will be extracted from the database. An important feature of relational system is that a single database can be spread across several tables. Today, popular RDBMS include Oracle, SQL Server, MySQL, PostgreSQL, etc.
Terminology Used in a RDBMS
- Table A table is the basic storage structure of RDBMS. A table holds all the data necessary about something in the real world, e.g. employees, invoices or customers.
- Row A single row or tuple represents all data required for a particular entity.
- Column A column or attribute represents a specific type of data of different entities.
- Degree It represents the number of attributes in a relation.
- Cardinality It represents the number of tuples in a relation.
- Primary Key A primary key constraint is a column or set of columns that uniquely identifies each row in a table. This constraint enforces uniqueness of a column or column combination. The primary key column cannot contain null value.
- Foreign Key The foreign key identifies a column or a set of columns in one (referencing) table that refers to a column or set of columns in another (referenced) table. The columns in the referencing table must be the primary key or other candidate key in the referenced table.
- Candidate Key All column combinations inside a relation that can serve as primary key are called candidate keys.
- Alternate Key A candidate key that is not Primary Key in a table.
- Domain Refers to the description of an attribute’s allowed values. It is actually a set of values the attribute can have, and the semantic, or logical, description is the meaning of the attribute.
- View In database management systems, a view is a particular way of looking at a database. A single database can support numerous different views.
SQL Commands
SQL commands are instructions used to communicate with the database to perform specific task that work with data. SQL commands can be used not only for searching data from the database but also to perform various other functions, e.g. you can create tables, add data to tables or modify data, drop the table, set permissions for users. SQL commands are grouped into four major categories depending on their functionality.
- Data Definition Language (DDL) These SQL commands are used for creating, modifying and dropping the structure of database objects. The commands are CREATE, ALTER, DROP, RENAME, TRUNCATE and COMMENT.
- Data Manipulation Language (DML) These SQL commands are used for storing, retrieving, modifying and deleting data. These commands are SELECT, INSERT, UPDATE and DELETE.
- Transaction Control Language (TCL) These SQL commands are used for managing changes affecting the data. These commands are COMMIT, ROLLBACK and SAVEPOINT.
- Data Control Language (DCL) These SQL commands are used for providing security to database objects. These commands are GRANT and REVOKE.
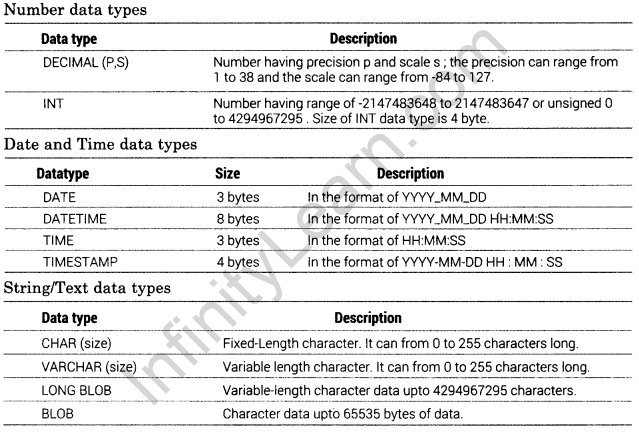
Data Types
Data types are properties of each field. Data types are means of identifying the type of data and associated operations for handling it.
Database Commands
Create a database
To create a database, CREATE DATABASE statement is used. Basic syntax of CREATE DATABASE statement is as follows:
CREATE DATABASE DatabaseName;
Database name should always be unique within the RDBMS.
e.g. CREATE DATABASE dname;
This query create a database named “dname”.
- Showing Databases MySQL provides a SHOW statement that displays information about databases and the tables in them.
e.g. SHOW databases; This query will list the available databases. - Selecting Databases The USE statement selects a database to make it the default database for a given connection to the server. The syntax is USE db-name.
e.g. Use school; Here, school is the database you want to select. - Dropping Databases Database can be removed or deleted using the DROP command.
e.g. DROP database reeta; This query will delete the database reeta permanently.
SQL CREATE TABLE Statement
The CREATE TABLE statement is used to create tables to store data.
The syntax for the CREATE TABLE statement is
CREATE TABLE table_name ( col umn_namel datatype(size), column_name2 datatype(size), : column_nameN datatype(size) );
- CREATE TABLE defines a new table.
- table_name is the name of the table.
- column_namel, column_name2… are the names of the columns.
- datatype is the datatype for the column like char, date, number, etc.
- size is the size of column that a cell can hold.
e.g. if you want to create the EMPLOYEE table, the statement would be like
CREATE TABLE EMPLOYEE ( id INTEGER, name CHAR(20), dept CHAR(10), age INTEGER, salary INTEGER, location CHAR(10) );
Displaying a Table Structure
If you have created a table in database, you may want to display its structure by using the DESC command.
Syntax DESC <table_name>; or DESCRIBE <table_name>;
e.g. DESC EMPLOYEE; will represent the tabular description of this table like field, type, key, etc.
SQL ALTER TABLE Statement
The SQL ALTER TABLE statement is used to modify the definition (structure) of a table by modifying the definition of its columns.
The ALTER command is used to perform the following functions:
- Add, drop, modify table columns
- Add and drop constraints
- Enable and disable constraints
Syntax To add a column
ALTER TABLE table_name ADD column_name datatype(size);
e.g. to add a column “experience” to the EMPLOYEE table, the query would be like
ALTER TABLE EMPLOYEE ADD experience INTEGER;
Syntax To drop a column
ALTER TABLE table_name DROP col umn_name;
e.g. to drop the column “location” from the EMPLOYEE table, the query would be like ALTER TABLE EMPLOYEE DROP location;
Syntax To modify a column
ALTER TABLE table_name MODIFY column_name datatype!size);
e.g. to modify the column “salary” in the EMPLOYEE table, the query would be like
ALTER TABLE EMPLOYEE MODIFY salary DECIMAL;
SQL RENAME Statement
The SQL RENAME statement is used to change the name of the table or a database object. Syntax To rename a table
RENAME old_table_name To new_table_name;
e.g. to change the name of the table EMPLOYEE to MY_EMPLOYEE, the query would be like
RENAME EMPLOYEE To MY_EMPLOYEE;
Inserting Data into Table
INSERT INTO statement is used to add a new row to a table and to insert data into table.
Syntax INSERT INTO table_name (Columnl, Column2, Column 3---) VALUES (Value 1, Value 2, Value 3- - -); or INSERT INTO table name VALUES (Valuel, Value2, Value3, ...);
With this syntax, only one row is inserted at a time.
e.g. to insert record of new student into STUDENT_DETAILS table, you could use the following statement.
INSERT INTO STUDENT_DETAILS (first_name, last_name, roll_No, class) VALUES (‘Ritika’, ‘Sheoran’, 45, 11); or INSERT INTO STUDENT_DETAILS VALUES (‘Ritika‘Sheoran’, 45,11);
Inserting Rows with NULL Values
To insert NULL value in a specific column, you can type NULL without quotes and NULL will be inserted in that column.
e.g. INSERT INTO STUDENT_DETAILS VALUES (‘Ritika’, NULL, 45,11);
SQL SELECT Statement
The most commonly used SQL statement is SELECT statement. The SQL SELECT statement is used to query or retrieve data from a table in the database.
Syntax of SQL SELECT statement for selecting all columns.
SELECT * FROM table_name;
for selecting specific columns.
SELECT columnjist FROM table_name;
column_list includes one or more columns from which data is retrieved.
e.g. SELECT * FROM STUDENTSJDETAILS;
it will display all records in tabular format.
e.g. SELECT first_name, last_name, roll_No FROM STUDENT_DETAILS;
It will display only records of first_name, last_name and roll_No of the STUDENT_DETAILS table.
SQL Alias
SQL alias is used to display more descriptive column headings. It immediately follows the column name (there can also be the optional AS keyword between the column and alias). The double quotation marks are required if it contains spaces or special characters or if it is case sensitive.
e.g. to select the first name of all students, the query would be like aliases for columns
SELECT first_name AS Name FROM STUDENTJDETAILS; or SELECT first_name Name FROM STUDENT_DETAILS;
In above query, the column ‘first_name’ is given alias ‘Name’. So, when the result is displayed the column appears as ‘NAME’ instead of ‘first_name’.
Distinct or Unique Keyword
By default the result of queries, included all duplicate rows. To eliminate duplicate rows from the result of a SELECT statement, we use the keyword DISTINCT or UNIQUE.
e.g. to select the distinct department_id from table employees
SELECT DISTINCT departmentjd FROM EMPLOYEES; or SELECT UNIQUE departmentjd FROM EMPLOYEES;
SQL WHERE Clause
The WHERE clause is used when you want to retrieve specific information from a table excluding other irrelevant data. e.g. when you want to see the information about students in class 10th only, then you do not need the information about the students in other classes. So, SQL offers a feature called WHERE clause which can use to restrict the data that is to be retrieved. The condition you provide in the WHERE clause filters the rows retrieved from the table and gives you only those rows which you expected to see. WHERE clause can be used along with SELECT, DELETE, UPDATE statements.
Syntax of SQL WHERE clause is
WHERE (column or expression) comparison-operator value
- Column or Expression is the column of a table or an expression.
- Comparison-Operator operators like =, < >, etc. .
- Value any user value or a column name for comparison.
Syntax for a WHERE clause with SELECT statement is
SELECT column_list FROM table_name WHERE condition; e.g. SELECT roll No FROM STUDENT WHERE marks> 60;
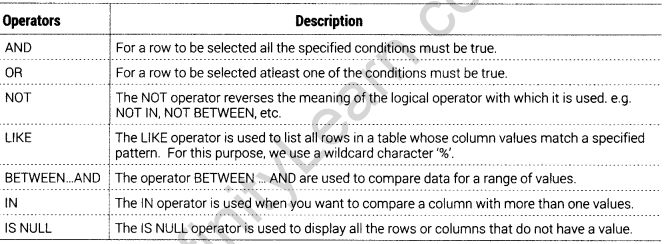
SQL Operators
An operator is a reserved word or a character used primarily in an SQL statement’s WHERE or HAVING clause to perform operations, such as comparisons and arithmetic operations. Operators are used to specify conditions in an SQL statement and to serve as conjunctions for multiple conditions in a statement.
There are four types of operators given below:
- Arithmetic Operators
- Comparison Operators
- Logical Operators
- Set Operators
Arithmetic Operators
Arithmetic operators are used to perform mathematical functions. There are four conventional operators for mathematical functions as:

Comparison Operators
Comparison operators are used to compare the column data with specific values in a condition. Comparison operators are also used along with the SELECT statement to filter data based on specific conditions.
There are following comparison operators as:

Logical Operators
Logical operators test for the truth of some conditions. They returns a true or false value to combine one or more true or false values. There are following logical operations:
SET Operators
SET operators are used to combine the results of two queries into a single result.
1. UNION
The UNION is used to return all the distinct rows selected by either query.
e.g. (SELECT SName FROM STUDENT WHERE stream = "science”) UNION (SELECT SName FROM STUDENT WHERE stream = “Arts”);
2 . UNION ALL
The UNION ALL is used to return all the rows selected in a query, including the duplicates also.
e.g. (SELECT SAL FROM EMP WHERE Job=“MANAGER”) UNION ALL SELECT SAL FROM EMP WHERE Job= "ANALYST”);
3. Intersect and Intersect All
It returns all the common rows selected by both queries.
e.g. (i) (SELECT *FR0M PRODUCT) INTERSECT (SELECT *FR0M CUSTOMER); (ii) (SELECT *FR0M PRODUCT) INTERSECT ALL (SELECT *FR0M CUSTOMER);
4. MINUS
The MINUS operator is used to return all the distinct rows selected by the first query but not the second query.
e.g. (SELECT SAL FROM EMP WHERE Job=“MANAGER”) MINUS (SELECT SAL FROM EMP WHERE Job = “ANALYST”);
SQL ORDER BY
The ORDER BY clause is used in a SELECT statement to sort results either in ascending (ASC, the default) or descending (DESC) order. SQL sorts query results in ascending order by default.
Syntax For using SQL ORDER BY clause to sort data is
SELECT column-list FROM table_name ORDER BY column1 ASC/DESC,, column2 ASC/DESC; ..columnN ASC/DESC;
Changing Data in a Table
UPDATE statement is used to modify the existing rows. We can update more than one row at a time.
e.g. to change the roll_no of a particular student from STUDENT_DETAILS table, you need to write the following command.
UPDATE STUDENT_DETAILS SET roll_No = 20 WHERE first_Name = ‘RAKSHU’;
Removing a Row from a Table
DELETE statement is used to delete rows from the table. We can delete more than one row at a time. e.g. to delete a record of student from STUDENT_DETAILS table, you need to write following command:
DELETE FROM STUDENT_DETAILS WHERE first_name = ‘Aaditya’;
You can also delete the all rows from table by existing the following command:
DELETE FROM table_name; e.g. DELETE FROM STUDENT_DETAILS; It will delete all rows from student_details table.
Concept of Database Transaction
Collection of operations that forms a single logical unit of work is called a transaction. In other words, transactions are units or sequences of work accomplished in logical order, whether in a manual fashion by user or automatically by some sort of a database program. In a relational database using SQL, transactions are accomplished using the DML (Data Manipulation Language) command.
A transaction can either be one DML statement or a group of statements. When managing groups of transactions, either each designated group of transactions must be successful as one entity or none of them will be successful.
The following points describe the nature of transactions:
- All transactions have a beginning and an end.
- A transaction can be saved or undone.
- If a transaction fails in the middle, no part of the transaction can be saved to the database.
Each transaction, generally involves one or more data manipulation language statements and ends with either a COMMIT to make the changes permanent or ROLLBACK to undo the changes. A transaction comprises a unit of work performed within a database management system (or similar system) against a database and treated in a coherent and reliable way independent of other transactions.
Transactions in a database environment have the following two main purposes:
- To provide reliable units of work that allow correct recovery from failures and keep a database consistent even in cases of system failure, when execution stops (completely or partially) with unclear status.
- To provide isolation between programs accessing a database concurrently. If this isolation is not provided the program’s outcome are possibly erroneous.
ACID Properties
ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably. In the context of databases, a single logical operation on the data is called transaction, e.g. a transfer of funds from one bank account to another, even though that might involve multiple changes (such as debiting one account and crediting another), is a single transaction. Jim Gray defined these properties of a reliable transaction system in the late 1970s and developed technologies to automatically achieve them. In 1983, Andreas Reuter and Theo Haerder coined the acronym ACID to describe them.
Atomicity
Atomicity requires that each transaction is “all or nothing”; if one part of the transaction fails, the entire transaction fails and the database state is left unchanged. An atomic system must guarantee atomicity in each and every situation, including power failures, errors and crashes.
Consistency
It ensures that any transaction will bring the database from one valid state to another. Any data written to the database must be valid according to all defined rules, including but not limited to constraints, cascades, triggers and any combination of them.
Isolation
The isolation property ensures that the concurrent execution of transactions results in a system state that could have been obtained, if transactions are executed serially i.e. one after the other.
Durability
Durability means that once a transaction has been committed, it will remain so, even in the event of power loss, crashes or errors. In a relational database, e.g. once a group of SQL statements executes, the results need to be stored permanently (even if the database crashes immediately thereafter).
Transactions in SQL
SQL is inherently transactional and a transaction is automatically started when another ends. Some databases extend SQL and implement a START TRANSACTION statement, but while seemingly signifying the start of the transaction it merely deactivates AUTOCOMMIT. The result of any work done after this point will remain invisible to other database users until the system processes a COMMIT statement.
A ROLLBACK statement can also occur, which will undo any work performed since the last transaction. Both COMMIT and ROLLBACK will end the transaction and start a new. If AUTOCOMMIT was disabled using START TRANSACTION, AUTOCOMMIT will often also be re-enabled. Some database systems allow the synonyms BEGIN, BEGIN WORK and BEGIN TRANSACTION and may have other options available.
Distributed Transactions
Database systems implement distributed transactions as transactions against multiple applications or hosts. A distributed transaction enforces the ACID properties over multiple systems or data stores and might include systems such as databases, file systems, messaging systems and other applications. In a distributed transaction, a coordinating service ensures that all parts of the transaction are applied to all relevant systems. As with database and other transactions, if any part of the transaction fails, the entire transaction is rolled back across all affected systems.
Transactional Control
Transactional control is the ability to manage various transactions that may occur within a relational database management system.
Note Keep in mind that transaction is a group of DML statements. When a transaction is executed and completed successfully, the target table is not immediately changed, although it may appear so according to the output. When a transaction successfully completes, there are transactional control commands that are used to finalise the transaction. When the transaction has completed, it is not actually taken changes on the database, the changes reflected are temporary and are discarded or saved by issuing transaction control commands. It can be explained through the given illustrative figure:
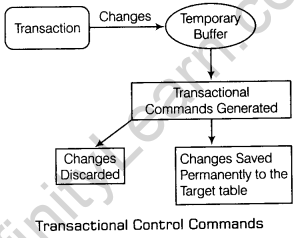
There are three commands used to control transactions:
1. COMMIT Command
The commit command saves all transactions to the database, since the last COMMIT or ROLLBACK command.
Syntax mysq1>C0MMIT [work];
The keyword COMMIT is the only mandatory part of the syntax. Keyword work is optional; its only purpose is to make the command more user friendly.
e.g. mysql>DELETE FROM BMP WHERE emp_age>75;
The above command deletes the records of those employees whose age is above 75 yr. Though the changes are reflected on database, they are not actually saved. As explained above, they are stored in temporary area. To allow changes permanently on database COMMIT command is used,
e.g. mysql>C0MMIT WORK;
The above command will make changes permanently on database, since last COMMIT or ROLLBACK command was issued.
2. ROLLBACK Command
The ROLLBACK command is the transactional control command used to undo transactions that have not already been saved to the database. The ROLLBACK command can only be used to undo transactions, since the last COMMIT or ROLLBACK command was issued.
Syntax mysql >R0LLE5ACK [work];
The keyword ROLLBACK is the only mandatory part of the syntax. Keyword work is optional; Its only purpose is to make the command more user friendly.
e.g. mysql >DELETE FROM EMP WHERE emp_age >75;
The above command deletes the records of those employee whose age is above 75 yr. Though the changes are reflected on database, they are not actually saved as explained above, they are stored in temporary area. To discard changes made on database ROLLBACK command is used.
mysql> ROLLBACK WORK;
The above command will discard changes made on database, since last COMMIT or ROLLBACK command was issued.
Note Work is totally optional, it is just to make command more user friendly.
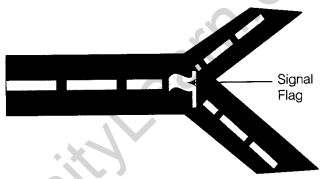
3. SAVEPOINT Command
A savepoint is a point in a transaction to which you can roll the transaction without rolling back the entire transaction.
Consider that a person walking and after passing some distance the road is split into two tracks. The person was not sure to choose which track, so before randomly selecting one track he make a signal flag, so that if the track was not the right one he can rollback to signal flag and select the right track. In this example, the signal flag becomes the savepoint. Explanatory figure is as given above.
Syntax mysql>SAVEPOINT
Savepoint name should be explanatory.
e.g. before deleting the records of an employee whose age is above 75 yr, we are not sure that whether we are given work to actually delete the records of an employee whose age is above 75 yr or 80 yr. So, before proceeding further we should create savepoint here, if we have been ordered later, then it might not create loss of information.
mysql>SAVEPOINT orignally; mysql>DELETE FROM EMP WHERE emp_age>75;
The above command deletes the records of those employees whose age is above 75 yr. Though the changes are reflected on database, they are not actually saved as explained above, they are stored in temporary area. After sometime, we have given order to increase employee salary to 10%. We can increase by generating following command. But before that we will make savepoint to our data so in case if the top level management changes their mind and order’s no increment should be given, then we can simply pass rollback entry to achieve present state.
mysql>SAVEP0INT increase_sal; mysql>UPDATE EMP SET salary=salary+(salary*.10);
It will increase the salary of each employee by 10%.
After sometime, if top level management decides that salary of only programmer should be increased by 10%, then only thing we have to do is just to pass command of rollback before salary is updated.
mysql>R0LLBACK increase_sal;
It will rollback the changes made to emp_salary, now we can update salary records only for those employees who are programmers. If we have doubt, then we can put savepoint, otherwise savepoint is not compulsory.
mysql>UPDATE EMP SET salary=salary + (sal ary*.10); WHERE emp_status= ‘PROGRAMMER’;
It will increase salary of only programmers.
If all the changes have been taken place and now, we have decided that no further changes are required and we have to made changes to apply on database permanently, then we can simply generate COMMIT command to reflect changes permanently on database.
mysql>COMMIT work;
We hope the given CBSE Class 12 Informatics Practices Notes Chapter 10 Fundamentals of Database Pdf free download will help you. If you have any query regarding NCERT Class 12 Informatics Practices Notes Chapter 10 Fundamentals of Database, drop a comment below and we will get back to you at the earliest.
